 © xkcd.com
© xkcd.com

Due midnight Sunday November 10
Steadily increasing computing power and memory plus a huge amount of data has made it possible for computers to do a decent job on many tasks that normally would require a human. Artificial intelligence, machine learning, and natural language processing (AI, ML, NLP) have been very successful for games (computer chess and Go programs are better than the best humans), speech recognition (think Alexa and Siri), machine translation, and self-driving cars (Zoox, anyone?). And in the past year, large language models like ChatGPT have shown remarkable abilities in "understanding" language, answering questions, carrying on conversations, and generating a great deal of well-written text, some of which is accurate.
There are zillions of books, articles, blogs and tutorials on machine learning, and it's hard to keep up. This overview, Machine Learning for Everyone, is an easy informal introduction with no mathematics, just good illustrations. It predates large language models like ChatGPT, however, so it's missing a major topic. But it's worth a quick look.
This lab is an open-ended exploration of a few basic topics in ML. The hope is to give you at least some superficial experience, and as you experiment, you should also start to see how well these systems work, or don't. Your job along the way is to answer the questions that we pose, based on your experiments. Include images that you have captured from your screen as appropriate. Submit the result as a web page, using the mechanisms that you learned in the first two or three labs. No need for fancy displays or esthetics; just include text and images, suitably labeled. Use the template below so we can easily see what you've done.
This lab has been significantly reworked from last year so it still has rough edges. Don't worry about details, but if you encounter something that seems seriously wrong, please let us know. Otherwise, have fun and see what you learn.
HTML template for your submission
Part 1: Machine Learning
Part 2: Image Generation
Part 3: Large Language Models
Part 4: A Python Version
Submitting your work
In this lab, we will highlight instructions for what you have to submit in a yellow box like this one.
For grading, we need some uniformity among submissions, so use
this template
to collect your results as you work through the lab:
Put a copy of this template in a file called lab7.html and as you work
through the lab, fill in each part with what we ask for, using HTML tags
like the ones that you learned in the first few labs.
There is an enormous range of algorithms, and much research in
continuing to improve them. There are also many ways in which machine
learning algorithms can fail -- for example, "over-fitting", in which
the algorithm does very well on its training data but much less well on
new data -- or producing results that confirm biases in the training
data. This is an especially sensitive issue in applications like
sentencing or predicting recidivism in the criminal justice system.
One particularly effective kind of ML is called "deep learning"
because its implementation loosely matches the kind of processing
that the human brain appears to do. A set of neurons observe low-level features;
their outputs are combined and fed into another set of neurons that observe
higher-level features based on the lower level, and so on.
Deep learning has been very effective in image recognition, and
that's the basis of this part of the lab.
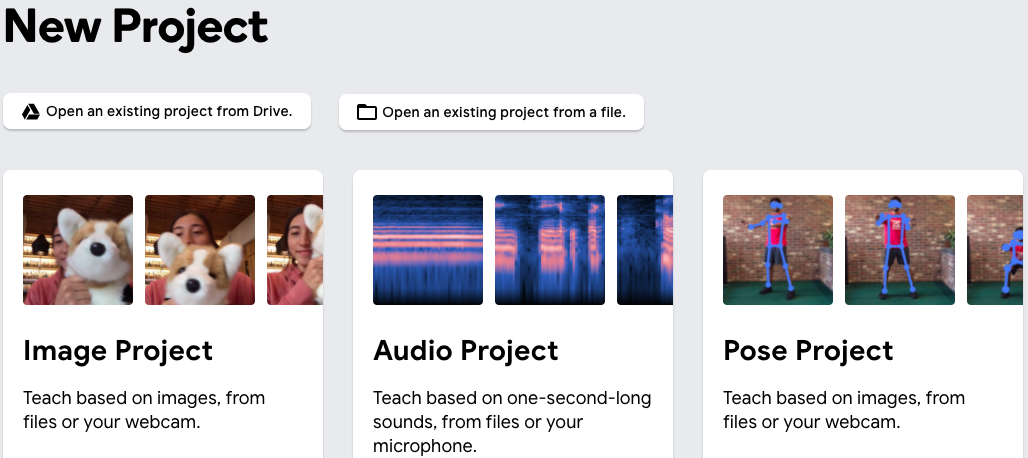
Google's
Teachable Machine
is a web application that uses the camera and microphone on a computer
to train a neural network on multiple visual or auditory inputs; the
interface looks like this:
I trained the network on two images, holding a pen in one
of two orientations. It's an easy case, and the recognizer is quite good at
distinguishing them.
Your job is to do some comparable but hopefully more interesting and
challenging examples of your own, and report on what you discovered.
Machine learning models have been steadily improving in
their ability to generate language and images that can often
appear as if they were generated by people.
One of the most interesting examples marries language
models to image tags to generate surprisingly creative images
from a "prompt", perhaps a dozen words that approximately
describe an image that might exist in the world, or might be entirely
synthetic. Here's a stunning example, the
AI-generated Théâtre D’opéra Spatial:
Most such images are nowhere near that good, but they do
show promise.
For example, this set of images comes from
Stable Diffusion
with the prompt
"A bearded elderly male professor teaching programming
to a class of bored humanities majors":
More seriously, some prompts produce decently good
results; for instance,
"a gray cat sitting at a door watching squirrels in the
style of van gogh's starry night":
The purpose of this section is for you to explore this area
a little, generate a handful of images that you like, and have
some fun while seeing what works and what doesn't.
The images above were generated by Stable Diffusion.
You can also use alternatives like
DALL-E2 from OpenAI
or a
DALL-E3 version from Microsoft.
These require you to create an account,
though use is free up to a point.
These systems are fun to play with, and impressive
in their capabilities. Archie McKenzie '24 suggests some tips that might
help image quality; these were for DALL-E2 originally but should
be helpful for other systems as well.
Certainly! ChatGPT is a friendly AI companion that uses the power of
computers to have conversations with people. Imagine ChatGPT as a
virtual friend who loves to chat about a wide range of topics. It can
answer questions, provide information, and even help with creative
writing or problem-solving.
What makes ChatGPT special is its ability to understand and generate
human-like text. It doesn't need to be programmed for specific
conversations; instead, it has learned from a vast amount of text from
the internet, books, and other sources. This means it can chat about
everything from history and science to movies and hobbies. You can talk
to it by typing messages or questions, and it responds just like a text
conversation with a friend.
In a nutshell, ChatGPT is like having an intelligent virtual buddy you
can talk to whenever you want, and it's especially helpful when you're
curious or need information, even if you're not into computer science or
programming. It's designed to make technology feel more approachable
and helpful for everyday conversations and tasks.
ChatGPT appeared in late November, 2022, and has been enormously
influential. It does a remarkably good job of generating well-written
English prose, it can answer questions over a wide range of areas
(often though not always correctly), it can translate to and from other
languages, and it does all this through a conversational interface that
often feels like talking to another person. In that sense, it
does seem to pass the Turing test.
There are plenty of competitors to ChaptGPT. I personally like
Claude, from Anthropic; anecdotally,
it does at least as well on text and it's very good at generating
code. Naturally, your mileage may differ.
Your job is to play with ChatGPT or one of its competitors, to
get a sense of the good bits and the failures. For example, you might
ask it to explain some part of the course that you have trouble with
or that you think needs a better explanation.
You should also apply it to one question from one of the problem sets.
Does it do well or does it make mistakes?
You can access ChatGPT at
chat.openai.com,
and Claude at
claude.ai/chat.
You will have to register to get access; the free account will give you
enough computing resources for experimenting for this lab. If you
prefer, you can use a different LLM; just tell us which one(s) you used.
If you want to try out your newly acquired Python expertise,
you can use the Python API for ChatGPT. It's pretty easy to set up a
basic conversational interface. You need to get a (free) API key from
OpenAI that is stored in your program to identify you
when you run the program. You can do the sign-up at
platform.openai.com.
Here's a simple example program, courtesy of Archie McKenzie '24,
who was the COS 109 undergrad assistant for several years; it's been
slightly fiddled by me. If you copy it into a file, or paste
it into a Colab window, it should "just work". ™
Alternatively, Claude has an API, and you could try that, or some
combination.
If you choose to do this optional section, let us know what you did,
what worked, what was harder than it should have been.
HTML template for your submission
<html>
<title> Your netid, your name </title>
<body>
<h3> Your netid, your name </h3>
Any comments that you would like to make about the lab,
including troubles you had, things that were interesting,
and ways we could make it better.
<h3>Part 1</h3>
<h3>Part 2</h3>
<h3>Part 3</h3>
<h3>Part 4</h3>
</body>
</html>
If you include big images, please limit their widths to
about 80% of the page width, with <img ... width="80%">, as in earlier labs.
Part 1: Machine Learning
"Machine learning algorithms can figure out how to perform important
tasks by generalizing from examples."
Most machine-learning algorithms have a similar structure. They "learn"
by processing a large number of examples that have been labeled with the
correct answer, for example, whether some text is spam or not, or which
digit a hand-written sample is, or what kind of animal is found in a
picture, or what the price of a house is. Using this training set, the
algorithm figures out parameter values that enable it to make good
classifications or predictions about new inputs.

Part 2: Image Generation



Part 3: Large Language Models
I said to ChapGPT
"Write two or three paragraphs that explain ChatGPT to a non-technical
reader with only a limited interest in and knowledge of computer science
and programming."
Part 4: (Optional) Using Python with LLMs
import openai
openai.api_key = "YOU NEED ONE OF YOUR OWN" # register with OpenAI to get one
# replace this with your own system prompt:
system_prompt = '''Perform name-entity recognition: Identify proper names of people,
names of places, names of institutions, etc., in the following text. Print names
of people and names of places separately.'''
messages = [ { "role": "system", "content": system_prompt } ]
while True:
user_content = input("enter text:\n")
messages.append( { "role": "user", "content": user_content } )
result = openai.ChatCompletion.create(model="gpt-3.5-turbo", messages=messages )
print(result.choices[0].message.content)
messages.append(result.choices[0].message)